
ATLAS e-News
23 February 2011
Can't stop the run
25 January 2010
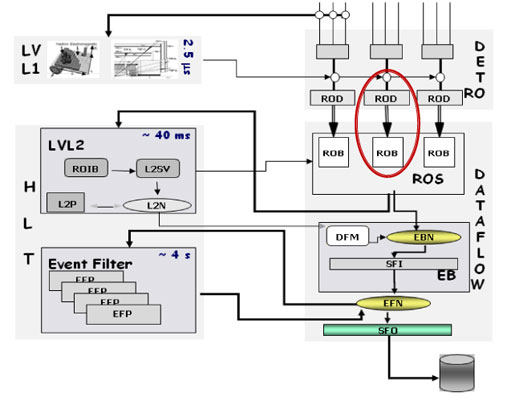
ATLAS data flows from the detector (top of the diagram) and reaches the Read Out Drivers
in the counting rooms. The data is buffered in the Read out buffers (ROB) awating for a trigger L2 decision.
In case a detector unit is not sending data anymore, the corresponding ROB link is removed
from the dataflow and can be reincluded once the corresponding detector unit has been
reconfigured and resynchronised.
The fact that the LHC isn’t circulating beam doesn’t mean that the Control Room gets a break. Run Coordination is busy with trigger tests, stopless expert system, integration of the innermost forward precision muon chambers, and noise hunting. And with the machine restart just over a month away, they are anticipating how the LHC operation team will ramp up the beam.
Every Monday, TDAQ takes simulated data and runs it through the trigger chain, testing each step of ATLAS data acquisition. “It’s actually a very rigorous procedure,” says Christophe Clement, Run Coordinator. The trigger calls up offline reconstruction algorithms to analyse whether an event is worth keeping, and the TDAQ is currently integrating a new release. These tests look for any unexpected consequences of the changes to the software.
Stopless mechanisms have been an important part of the work, ensuring that if one small part of ATLAS stops transmitting data, the detector can continue to read out events, merely ignoring the problematic element as long as it is small enough. Most parts of ATLAS already have the “removal” mechanism in place, telling the readout software not to wait up for a non-responding module.
The Transition Radiation Tracker, Tile Calorimeter and parts of the Muon system have recovery procedures as well. In case of problem, a readout unit can step out of the data stream, be reinitialised, resynchronised with the rest of ATLAS, and jump back in again without bringing the detector to a halt.
For now, the recovery system would send a pop-up window to its subdetector team in the control room, getting permission to rejoin the data-taking, but eventually, Christophe says that these systems, once well understood, will be entirely automatic.
Since not all parts of ATLAS have stopless recovery, Run Coordination is also concerned with establishing a “pain threshold” for each subdetector – the maximum number of channels that can be removed before the data is no longer useful. If time allows, they would also like to reduce the size of the smallest piece of detector that can be stopped, improving the granularity of the system.
Apart from the stopless removal and recovery mechanisms, information about what channels have been switched off needs to be embedded into the data that collaborators will be accessing offline for physics analysis.
Last week, the TRT underwent recovery and poll mode tests, then the Central Trigger Processor ran with the TRT and the precision muon chambers (RPC and MDT) from Wednesday to Friday. This exercise checked whether the Level 1 trigger responds to the muon chambers, and the data is also used for the calibration of the MDTs.
This week, the calorimeters will run together for calibration of the L1Calo trigger and to test the high level trigger (HLT). The trigger team got a head start on the final HLT software, installing it last the week before last.
From the second week in February, ATLAS will perform a full cosmic run with magnets. The various subsystems will also perform high rate tests of the trigger and readout to make sure that it won’t shut down as the machine teams ramp up the LHC’s luminosity. “Until the end of 2009, we were running a reasonably low Level 1 rate, so we just want to make tests to be sure that all detectors are able to run at the nominal rate,” says Benedetto Gorini, Deputy Run Coordinator.
Finally, detector groups are addressing an annoyance: noise. These fake signals for big events are fairly easy to spot and discard, but during a run, they could overshadow particles from a collision event. The process of finding the source of the noise is “quite painful,” according to Christophe. The variables are many and the clues are few, but a starting point has been the periodicity of the noise events.
Once at 7 TeV collision energy, the machine group will start adding more bunches, with 2 per beam, then four, then 16 and finally 43. With 43 bunches in each beam, they’ll introduce the crossing angle at ATLAS and begin to squeeze the beam, increasing the density of the bunches and chances for collisions, before increasing the bunch number.
The machine team is considering putting 156 bunches in each beam, but this step is not particularly useful to ATLAS. But with 144 bunches per beam, the accelerator group will shrink the spacing between bunches to 50 nanoseconds, with a crossing angle at all four experiments. Then, they’ll squeeze the beam again. From here, they can slowly increase the number of bunches from 144 by adding them to the end of the bunch train.
But from mid-February to mid-March, the accelerator team will stick with beam commissioning, with the 3.5 TeV run beginning the week of March 22nd (week 12).
 Katie McAlpineATLAS e-News
|