
ATLAS e-News
23 February 2011
Software status
15 November 2010
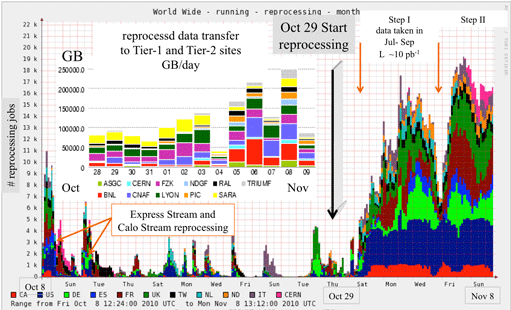
Number of jobs being sent to the Grid during the autumn reprocessing. The smaller peaks between the Calo Stream reprocessing and the recent bulk reprocessing relate to tests of the new release and group tasks.
With the Autumn reprocessing drawing to a close, soon the whole of the 'useful' ATLAS dataset all the 900 GeV and 7 TeV stable beam data ever taken will have been reconstructed with the same version of the software, leaving one huge uniform dataset ripe for physics analysis. This is the first major software update since the implementation of the frozen Tier 0 strategy, introduced in May, so what's new for Release 16?
“Mostly it's a bug-fix release,” reports Release Coordinator Nicolas Berger. “There were lots of things that were done in the previous release which were put in very quickly... So there's been a lot of cleaning up, straightening code out, and making sure things are done in a more rational manner.”
Having said that, between the final version of Release 15 and the first version of Release 16, about 800 of the 2000 packages were changed in one way or another, and since then a further 300 bug fixes have gone in. The changes may be tiny, but a lot of the code has been polished for this release.
Alignment precision is one area that has seen some important improvements; leaning on the large dataset at hand, the TRT alignment is now finer, done straw-by-straw rather than at the level of whole modules. Elsewhere, improvements to the way that multiple Pixel cell hits in the same module are resolved and clustered affects vertex reconstruction and b-tagging resolution, which will in turn boost physics performance for example the mass resolution in the &Zeta → µ µ channel.
“The alignment precision for the pixels went from 21 microns in the May processing to 15 microns in the current reprocessing, which is a very significant improvement,” says Nicolas.
One important customer for these tracking improvements is b-tagging, and there are preliminary studies with Release 16 data already starting to come out now which show very nice performance improvement.”
More general improvements include the interfaces being made more user-friendly and “memory leaks” being ironed out of the code. This is useful and necessary the improvements elsewhere tend to add memory usage and CPU time, but a typical Grid machine has a 2 GB memory.
“[Individual] programs should try to fit within this memory. If you go beyond 2 GB, reconstruction performance starts to drop somewhat,” cautions Nicolas. “The end result [for Release 16] is that we're basically at the same CPU and memory usage that we were at before. But with better functionality,” he smiles.
The reprocessing began on October 30th, with Release 16.0.2.3. This was used for the first week or so of jobs, before moving to an updated version, 16.2.0.4. The newer version takes account of changes which took place at Point 1 during the data-taking period, like changing trigger prescale factors. “We're basically back-porting recent changes in the data taking into this reprocessing release so that it can deal with our data,” explains Nicolas.
The new version also incorporates fixes for the kind of small code bugs and loops that pass by the test samples and only rear their heads when the code is run on millions of events. The two releases were checked with a sample of 7000 events, to ensure that 16.0.2.4 would come up with the same results as 16.0.2.3 for the data that has already been reprocessed.
In total, a billion data events and half a billion Monte Carlo events will be reprocessed. As we go to press 80 per cent of the data jobs are already complete, done within the first three weeks of reprocessing, but towards the end, the familiar 'long tail' of the last remaining jobs the one per cent which cause crashes and require their own bug fixes to be implemented will likely stretch out over a couple of weeks.
This latest release, 16.0.2.4, has already been frozen at Tier 0, ready to reconstruct new proton-proton data in the New Year which can flow straight on to the end of the existing dataset. And plans for Release 17 are already underway, with continued refinement of the Pixel clustering being high on the Task List.
 Ceri PerkinsATLAS e-News
|