
ATLAS e-News
23 February 2011
Picking pile-up to pieces
27 July 2010
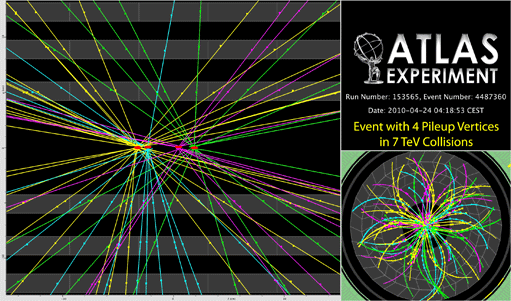
An event with with four reconstructed vertices (four overlaid minimum bias events)
In an ideal world, the LHC would smash protons together in ATLAS, and beautiful events would unfold, one at a time, under the watchful gaze of the experiment's electronics and software. Things are never that simple though, and with the thrill of increasing luminosity comes the pressure to catch events which start to arrive thick, fast, and concurrently.
‘Pile-up’
is distinct from ‘underlying events’
in that it describes events coming from additional proton-proton interactions, rather than additional interactions originating from the same proton collision.
The chances of producing more than one full-on proton-proton collision (a hard scattering event) per bunch crossing are pretty low. But as the instantaneous luminosity per bunch crossing effectively the density of protons in the interaction region where the beams overlap goes up, the likelihood of ‘ soft’
interaction between the constituent quarks and gluons of additional proton-proton pairs increases. The challenge for ATLAS then is working out which tracks and energy deposits to attribute to which interaction.
On top of this so-called ‘in-time pile-up’ comes concern about ‘out-of-time pile-up’, which refers to events from successive bunch crossings. Eventually, the LHC will carry 2808 proton bunches per orbit, making them exceptionally close in space and time: just 25 nanoseconds apart. This is faster than the read-out response of many of the ATLAS sub-detectors, so being able to identify which bunch crossing each particle originated from will be crucial.
“If you look at the detector in the transverse plane [a slice, staring right down the beam pipe], and look at how far a particle will travel, even at the speed of light, it has barely reached the outer side of the ATLAS detector before the next bunches of protons will already interact,” explains pile-up expert Giacinto Piacquadio.
Every sub-detector has worked hard to try to deal with overlapping energy deposits from successive bunch crossings at intervals of 25 nanoseconds. But for now at least, with only a few tens of well-spaced bunches in the machine, out-of-time pile up is not a concern. In any case, says Giacinto, "In-time pile-up will typically be much more dangerous. That is more difficult to disentangle from the event of interest because it happens at the same time.”
Giacinto is involved in developing primary vertexing algorithms in ATLAS, which try to reconstruct the vertices that charged particle tracks originate from, and are “one of the main ingredients” for dealing with the in-time pile-up problem.
Distinguishing overlapped vertices in the plane perpendicular to the beam, where the beam spot spans just 25 microns, however, is “extremely difficult”, considering that a typical pile-up vertex resolution is around 100 microns. They are much easier to pick out in the direction parallel to the beam, however, since their resolution is significantly better than their typical separation in this direction (here the interaction region spans 100 millimetres or so).
Picking out the ‘signal event’ the genuine proton-proton collision that caused the trigger to fire requires detective work. Generally, particles originating from this vertex will have much higher transverse momentum. The vertex reconstruction algorithms first try to find one single vertex, and throw away all the tracks that are incompatible with it. Then they go back to those discarded tracks and hunt for further vertices, repeating this process until, hopefully, all vertices have been found. This ‘signal vertex’ is selected as the one with the highest momenta tracks associated with it.
This is not fail-safe though. On the one hand, too many vertices can be reconstructed in cases where there are a high number of tracks, explains Giacinto: “Since even the track measurement is not perfect, at a certain point some of the tracks may be incompatible with the vertex. So the algorithm will create a new vertex nearby.”
To combat this, the algorithms have been designed to be conservative to assign close tracks to the same vertex which means that, on the other hand, genuinely separate vertices in close proximity are likely to get merged into one by the software.
“Of course, we'd never tested the vertex fitting algorithms on real data in the conditions we're facing now, which is more than one interaction per bunch crossing; up to six or even seven vertices per event,” Giacinto smiles.
Crunch time came on June 25th, when the LHC started running with nominal bunches containing 1.15 x 1011 protons. The average number of interactions per bunch crossing has leapt from around 0.1 to around 1.5, close to the maximum pile-up expected for this year's run, and so far the algorithms are looking good. Eventually, when the beams are fully squeezed, upping the chances of proton-proton interactions, this is expected to rise to 23.
Understanding how the number of vertices reconstructed relates to the real number of vertices and whether the algorithms have been made too conservative or not conservative enough is the next challenge. A dedicated vertexing group is already in place, studying how well the algorithms perform with data and comparing results with Monte Carlo expectations.
“The optimal compromise is for sure something that will have to be tuned in data,” says Giacinto. “This is something which is still ahead of us.”
 Ceri PerkinsATLAS e-News
|