
ATLAS e-News
23 February 2011
Memory vs. speed
5 October 2009
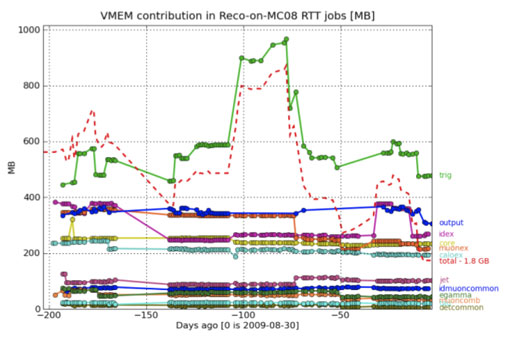
Memory consumption by the 12 different working groups' reconstruction code. The red dashed line shows the total memory consumption of all reconstruction code. At the start of July, you can see where the Muon group made 80GB of savings by minimising cache storage, and the jump in August was due to a bug which has now been fixed.
In the run-up to events, there has been a big effort to optimise both the reconstruction code and the simulation code. This week, we’re looking at how the reconstruction code has been tweaked over the last year to improve its efficiency and ensure its robustness ahead of beam.
For the reconstruction group, memory consumption has been the number one concern for the last year or so, with the processor-imposed limit of 2GB per job proving difficult to meet. Developers may write perfectly good standalone code, but the problem arises when the full set of algorithms is run together and the production is taken over the threshold limit. This is most commonly the case on ‘busy’ events like high luminosity pileup, or possible exotic events like black holes, which involve many particles and large energy deposits in the detector.
Until this year, it has been difficult to pinpoint where the blame lies; when a job crashes, it doesn’t necessarily do so while executing the particular algorithm that consumes the most memory, but rather at the point in the sequence when the memory limit is reached. Thanks to a new tool that maps memory consumption across 12 working groups, it is now possible to spot where memory is being monopolised and where individual developers might make improvements.
Since January, the tool has been used on the nightly runs to keep an eye on the effects of developers’ changes to their code. “We’re improving, but we will never get as low as one gigabyte,” says Reconstruction Integration Group co-ordinator, David Rousseau. “What we want is to be comfortably within two gigabytes, even for very busy events.”
When they’re lucky, developers’ alterations can have positive impact outside of their own code, and bring memory consumption down across the board. This can also work the other way though, with useful alterations in one area having a negative impact on others. The monitoring tool has proved invaluable for monitoring these fluctuations.
Historically, ATLAS developers have focussed on CPU demand and speeding up their code by computing items in advance and storing them in a cache. But there is a balance to be struck between speed and memory consumption. When the muon group abandoned some of their pre-calculating at the start of July, their code performed a few per cent slower than before, but the move freed up 80MB of space in an instant – a valid trade-off in David’s opinion.
Although trying to cap the memory of each job is critical for improving the software performance, there is also an argument for upping the cut-off point at which a job is dropped. The memory figure used when deciding whether a job can be run is actually the memory ‘potentially used’ by the job, but in practice the amount of memory used by the intelligent system is always lower.
Items in the code that are rarely called on are written out to disk, freeing up virtual memory for the more heavily used parts of code. But because the ‘memory potentially used’ figure doesn’t take account of this re-distribution of memory demand, a job can be killed before it has even been tried. It looks like a loosening of the cut-off point is on the horizon though, as many people have been working on persuading the computing site managers round to this way of thinking.
Of course, code optimisation is just half of the battle. The “cosmics to collisions” transition, as David calls it, is the other focus right now as the countdown to beam begins. Cosmic events come with the associated ‘real data’ challenges of noise, dead channels and potential data corruption, but are relatively simple compared with collision events. Monte Carlo simulations can test how the system copes with busy events, but they don’t account for the afore-mentioned real-world detector effects.
By attacking the problem from both ends – over 1 billion cosmic and Monte Carlo events have been reconstructed this year – the code has been thoroughly tested to ensure that it is robust and ready for beam.
A two-week “Big Chain Test” is currently underway, following the latest software release, 15.5.1. Several million events are being run over a few hours. This will be used along with the cosmic data that ATLAS will begin collecting from mid-October, to make final fixes to the code.
Of course, unexpected problems will still arise once data taking with beam begins, but the plan at this stage is not to plan too much; it would be a waste of time to project every possible scenario. Instead, efforts have been channelled into structuring the code in such a way that disabling elements of it for ad-hoc fixes will have limited knock-on effect on other algorithms, and won’t set off a ‘cascade of failures’.
More on summer-autumn 2009 software improvements:
Simulation slimdown

Ceri PerkinsATLAS e-News
|