
ATLAS e-News
23 February 2011
Moving from simulation to real data. Is your analysis ready?
16 November 2009
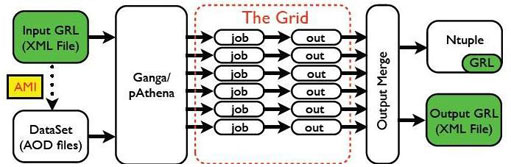
Data flow in the Analysis Model showing the use of Good Runs Lists in a distributed analysis job.
With first collisions expected before the end of the year, many users are eagerly preparing analyses for the first real collision data seen by ATLAS. After years (or even decades) of working with Monte Carlo samples, the transition to analyzing real collision data brings new challenges to the ATLAS collaboration.
To ensure the timely production of first physics results in 2010, the Analysis Model for the First Year (AMFY) task force was created and charged with reviewing the model and tools for early analyses of ATLAS data. The final AMFY report was delivered by task force chair Thorsten Wengler at the Barcelona ATLAS week, and the recommendations of this task force now serve as a blueprint for users preparing their analyses for first data. The corresponding document is still being reviewed and will be released soon.
The first challenge facing a user in preparing their analysis is to choose an appropriate source of data. The ATLAS data is written into separate streams sorted by the triggers which accepted the events. There are five physics streams defined (e/gamma, muon, minbias, B-physics, and jet/tau/missing ET), and each stream is inclusive meaning some events are duplicated across streams if they pass more than one type of trigger. The raw data files for each stream are reconstructed to produce Event Summary Data (ESD) and Analysis Object Data (AOD) files. The ESD contains all of the details of the event reconstruction, and is the likely starting point for detector performance studies. The AOD, which contains a subset of the information available in the ESD, is intended to be the starting point for physics analyses.
All events recorded in a given stream are present in the ESD or AOD file. Further size reduction is achieved by producing derived data formats where events are filtered based on reconstructed event properties, or some of the information present in the full ESD or AOD is removed. These dESD and dAOD files (formerly known as Derived Physics Data (DPD) files) are produced in several variants to meet the needs of combined performance and physics analysis groups respectively. The AMFY report expects that performance studies will start from dESD files, while physics analyses will start from either AOD or dAOD files, as both will be available to end users. An alternative to running over complete data samples is available in the TAG mechanism. This is especially attractive for analyses that expect to select a small subset of the total ATLAS data volume. More details on TAG-based selections can be found in this recent ATLAS eNews article by Elizabeth Gallas.
Despite the best efforts of the detector subsystems, not all data recorded by ATLAS will be suitable for inclusion into physics analyses. The primary tool for rejecting unsuitable data are data quality (DQ) flags which are produced by both the detector subsystems and the offline combined performance groups, and present a simple red/yellow/green “traffic light” indication of data quality. The system for evaluating and recording DQ flags is already being exercised at point 1 in the combined cosmic running, although a consensus for where to draw the line for “green” data will likely take some time to evolve. Indeed one of the main tasks facing each combined performance group will be to decide what combination of detector and offline DQ flags is necessary to define a usable sample of their offline objects.
The mechanism for selecting or rejecting data is based on the concept of Luminosity Blocks (LBs). ATLAS runs are subdivided into these smaller time intervals of approximately one minute over which it is assumed that the delivered luminosity is constant. The selection of a valid sample of data in practice means selecting a specific set of LBs from a range of runs based on DQ and potentially other criteria. A set of selected LBs is known as a Good Run List (GRL) and uniquely specifies the data sample desired for a given analysis. Since the information needed to produce a GRL is ultimately stored in the conditions (COOL) database, and users will sometimes want to use this information without direct database access, an XML (text) file format has been developed to allow this information to be exchanged between various ATLAS analysis tools. The Run Query Tool developed by Andreas Hoecker and Joerg Stelzer provides a convenient interface for users to browse data, examine DQ flags, and output GRL files.
Since a number of luminosity blocks may be stored in a given AOD or dAOD file, the user needs to reject unwanted luminosity blocks when their analysis job is run. The GoodRunsLists package, developed by Max Baak, is used in an Athena analysis job to reject data from unwanted LBs based on a GRL XML file which must be provided with the job. The GoodRunsLists package is also compatible with standalone use in a ROOT session to reject data from an ntuple in a similar way. For large distributed analysis jobs run on the grid, it is planned that GRLs will be produced centrally by the Data Quality group and saved on the grid for use by the distributed analysis system. This managed production of GRLs from configuration files provided by users will ensure stability and reproducibility of the data selected for physics results. More details on the creation and application of GRLs in an analysis job can be found in this tutorial.
A final step needed for many physics analyses is the integrated luminosity of the data sample. Since a GRL specifies a particular sample of data, the GRL is also the main ingredient in computing integrated luminosity. Balint Radics, working with the luminosity group, has developed a new iLumiCalc.exe executable as part of the LumiBlockComps package to calculate the integrated luminosity for a specific GRL based on the offline luminosity values computed by the luminosity group and stored in the conditions database. If desired, the user can also specify a trigger and the prescale and deadtime corrections will also be computed.
The same code which drives iLumiCalc.exe is also designed to be used in an Athena analysis job. In addition to providing luminosity information for each analysis job, this code, working with the GoodRunsLists package above, will provide an output GRL from your job indicating the exact luminosity blocks which were analyzed by the job, even if no events were actually selected in a given luminosity block. Without this information, it is impossible to accurately calculate the integrated luminosity of the entire data sample, particularly if an analysis starts with a dAOD file where some luminosity blocks may already have no events selected due to event filtering. As long as the LumiBlockComps and GoodRunsLists packages are used properly, the LB information about the entire data sample processed, and not just the events seen, will be properly accounted for. Further details on the use of the luminosity tools can be found at this TWiki page.
There has been considerable development in recent months bringing all the tools together to select, analyze, and understand the first data collected by ATLAS. In some places there are still some details to work out, but the basic framework recommended by the AMFY task force is ready for users to incorporate into their analysis jobs. As always, constructive feedback to the developers is much appreciated. Examples of how to access special Monte Carlo samples complete with fake DQ flags and luminosity information can be found at the Offline Computing Tutorial TWiki page.

Eric TorrenceUniversity of Oregon
|