
ATLAS e-News
23 February 2011
Optimising the reconstruction software performance
9 June 2008
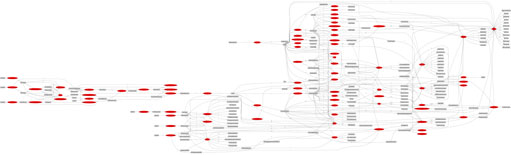 Diagram of the ATLAS reconstruction data-flow. Ellipses are
algorithms, rectangles are data objects. Click image for full size.
Diagram of the ATLAS reconstruction data-flow. Ellipses are
algorithms, rectangles are data objects. Click image for full size.
There are about 80 algorithms running in ATLAS reconstruction (and another 80 dedicated to treatment of Monte Carlo simulation). All these algorithms cooperate in an orderly manner to transform the raw data flowing out of the detector in a few collections of electrons, muons, jets etc. which are used for all physics analyses. And this is done for the billion events ATLAS will record every year, plus Monte Carlo simulation.
At any time we are about 100 people actively involved in the development of these algorithms or the common tools they use. We are spread around the world working in small groups striving to deliver the best software to maximise the efficiency and precision with which particles are reconstructed and identified. But of course, there are technical constraints.
One constraint that is on every developer's mind is the CPU time. For all these events to be reconstructed within one or two days on a dedicated cluster at CERN (the Tier-0 site), the processing of one average event should take less than 15 kSi2K seconds (meaning less than 6 seconds on a typical computer). In recent releases, this number is 20 kSi2K seconds.
The optimistic way of seeing this is that we are not too far off, which is a non-trivial achievement given that this goal was set almost 10 years ago. The pessimistic way is that we have no safety margin: what constitutes an "average event" depends on the trigger menu used, plus the effect of pile-up cannot be very well anticipated, and a very odd data event may cause problems, as was seen during commissioning with cosmic data.
We know that 80% of the time is spent in 20% of the algorithms (the well known Pareto's law for programming which has again been verified). This are still 30 algorithms which have already been scrutinised up to the point that there are no obvious inefficiencies anymore. Even if significant speed-up is still expected here and there through reoptimisation, we have to be ready to not run all available algorithms at the very beginning.
While redundancy of reconstruction algorithms is desirable, the focus of this year's data taking will be on understanding and calibrating the detector (see previous Atlas e-news). Hence the gain expected from running very sophisticated algorithms which necessitate accurate calibrations could be small.
Another constraint has become more important recently: the memory consumption. In the last five years, the CPU frequency has stopped increasing at 2.5 GHz. We are now offered dual, quadruple even octuple core machines. However, the memory available for each core is in fact more costly than the core itself. A good Grid machine today has 2 GB of memory per core, but a number of machines have less than that, so that we are already not using all the processors we could for reconstruction, due to lack of memory.
Currently the reconstruction uses about 2 GB of memory, which again is just at the limit. There has been a lot of effort to reduce the memory usage, sharing common tools, using float rather than double, optimising the caches etc., but at the same time, calibrations are being done in a more realistic way, in particular acknowledging the broken symmetry of the real detector. It has taken time to make developers aware of the memory problem. Anyone writing code is reasonably careful writing CPU-efficient code, because CPU inefficiencies hit any test program. On the other hand, a developer can write memory hungry code without even noticing...until it is integrated and the full reconstruction hits the wall!
The final challenge is robustness. Despite the algorithms being extensively tested on simulation and on real cosmic data events (and noise), bad surprises when real collision data comes are not unlikely. We can set as a goal the failure rate for the first bulk reconstruction to be less than 1% of the jobs (which would be salvaged in a subsequent reprocessing), each job processing up to 10,000 events. This corresponds to an event failure rate of less than one in a million events, which means each algorithm should have a probability of failure of less than 1 per 100 million events!
Given that we cannot expect each code modification to be tested to this level of precision, this is another reason to be ready to react quickly if a problem shows up. A number of efficient tools and automatic testing procedures have been developed to cope with the CPU, memory and robustness challenges, but, not surprisingly, it still takes human beings to improve our software.
|
|

David RousseauLAL-Orsay, CNRS/IN2P3 Univ Paris-Sud, France
|