
ATLAS e-News
23 February 2011
Improving data-taking before collisions
8 March 2010
The expected integrated luminosity from the LHC will be well below design luminosity this year but, for the data preparation teams, 2010 is “showtime”. The volume of data that will be collected over the run is expected to approach that of a year at design luminosity, meaning that the big challenges in terms of processing, reconstructing, and distributing data are already on, and efficiency must be at max.
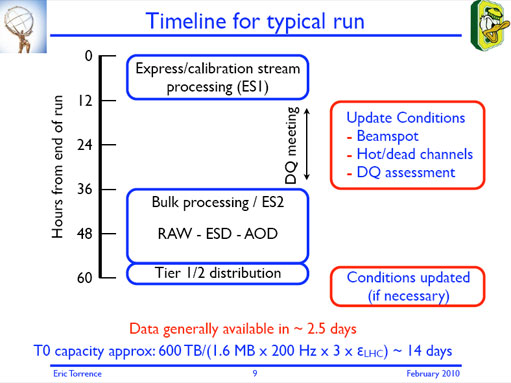
Amongst other recent tweaks to the working system, the single biggest change on the horizon is the introduction of the ‘prompt calibration loop’. When in place, this will put a delay of 36 hours or less between data coming off the detector and the time at which the bulk of it is first reconstructed. A small subset of data – an express stream containing the most exciting bits – will be processed immediately, for an at-a-glance look at whether there are any problems that need fixing in the online software or ahead of the full reconstruction.
“[This approach] was always in the model from way back, but it’s never really been implemented,” says ATLAS metadata co-coordinator, Eric Torrence. Back in December, all data – express stream and bulk – was processed concurrently, as soon as it was available; problems and calibration updates were simply marked to be dealt with later, at the reprocess stage. With only two weeks’ data taking, this was not an issue.
For this year’s constant running, data in the express stream and several focussed calibration streams will typically be reconstructed within eight hours of a run ending. In the fixed confines of the calibration loop, this gives detectors and sub-systems at least 24 hours to extract calibration constants and perform other checks that can’t be done in real-time, like pinpointing the position of the beam spot, or hunting and masking bad channels.
This information is fed into the conditions database – basically a detailed and dynamic picture of the state of the detector while data is being taken – and used later to inform the bulk reconstruction.
“Beam spot is a good example of something that moves around a lot,” explains Eric. “But if the tracking algorithm knows where the tracks should be coming from, it does a much better job than if it just has some nominal position which could be off by a millimetre or more. “
“[The calibration loop] is really a step in getting the best performance from each piece of the detector earlier in the process, rather than having to wait until the data is completely reprocessed weeks or months later.”
For now, performing these checks – comparing histograms with references – is done manually, but in the long-term, as people build trust in the programs that can extract the relevant information for them, this will become largely automated.
“But if something changes in a new way, then that code won’t necessarily catch it,” Eric warns, “so somebody still has to be there to verify the results.”
The prompt calibration loop won’t be implemented until a couple of weeks into stable 7 TeV operations. The real challenge at that point, according to Eric, will be the “endurance of keeping this up for months and months on end” once the novelty of new data wears off, and making these kinds of checks goes from new-and-exciting to more of a chore that simply has to be done. “That’s the reality of running a detector though,” Eric smiles.
Another stream that has received some attention ahead of the 2010 run is the debug stream. This is where especially busy events that time out, or those that crash the HLT algorithms (now a rare occurrence) are sent for later re-running. Where before, this was only available to the Trigger teams for searching out and fixing crash-causing bugs, it will now be made available to physics groups as a dataset on the Grid.
“It’s not intended that people will actually be doing physics on these, but they can check to see if all of their favourite signal events are ending up there for some reason,” explains Eric. In this way, physicists will be able to help to uncover any systematic biases in the Trigger.
Finally, Eric has been busy himself working on the ATLAS data summary page, a kind of teched-up version of ATLAS Now. This online resource (link, awaiting), will provide a snapshot of what data is being taken, updated every half hour or so.
“Part of the reason I got interested in it was because I’m usually 5000 miles and nine time zones out of the way, in Oregon, and it’s hard to follow what’s going on in day-to-day operations,” Eric explains. He envisages the primary consumer to be the Run Co-ordinators, but any ATLAS member can log on and monitor each LHC fill, keeping track of how much luminosity the machine delivered, what ATLAS recorded, when the detector was actually on, what the data taking efficiency looked like, and more. “The goal was to produce something where people could quickly see what was going on with data taking, wherever they are in the world.”
 Ceri PerkinsATLAS e-News
|