
ATLAS e-News
23 February 2011
Hack scare ruffles feathers in the Control Room
16 June 2009
"The system is down."
Picture the scene. You’re in the ATLAS Control Room. It’s 8pm on a Friday evening. Of course it is – don’t things always go wrong at the most inopportune moments?
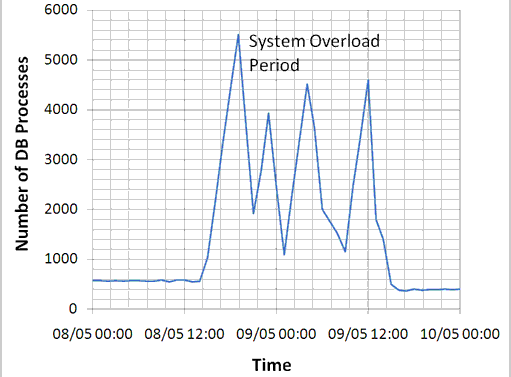
It’s Friday May 8th, to be exact, three and a half successful weeks into the recent cosmic run. ATLAS has been in combined running mode for the last five days, and right now, all seems to be going smoothly. And then the run stops.
This in itself is a fairly routine occurrence, but panic levels started to creep up when the cause of the abrupt interruption could not be found. “Nothing was working anymore,” remembers Detector Control System (DCS) Coordinator Stefan Schlenker. “Everyone was searching, calling experts, going, ‘Aaargh, what’s going on?!’ It was chaotic.”
The first piece of the puzzle was found when a rebel trigger process was spotted accessing the online database in the Computer Centre during runs. Conditions data – “basically the health of the detector” – is streamed constantly to the database, but configuration information like how the trigger is set up should only be accessed at the start of each run. Identifying and locating this illicit database interaction was the first clue to solving the mystery, but it still didn’t explain why the system had crashed.
In the hunt for answers, shifters contacted the database crew, only to discover that in fact, the whole database server had been floored, which, as Stefan puts it, is “quite some catastrophe”. Frantic investigations eventually revealed that the system had shut itself down because it was being inundated by mid-run DCS connection requests: “There’s a limit to how many the server can accept,” explains Stefan. “After that, it just says ‘no’.”
This ‘trip’ mechanism is intended to protect against any process that threatens the availability of the system and its resources, including hackers. Even though a recent security tightening made it impossible to reach the server from the general CERN network, let alone the outside world, the request bombardment looked suspiciously like a hack attempt. A firewall was put up straight away, but one process in particular, running inside the CERN computer cluster, was making literally thousands of connections. It was an alarming sight for the database team.
Eventually, the requests were pinned down to a specific user, and people set about trying to contact this mysterious character – who was in the US at the time – in earnest. In the meanwhile, System Administration had to perform an intervention and kill the process. The database was restarted, and everyone thought the storm had passed.
Until about six hours later, that is. In the early hours of the Saturday morning, the database administrators, now watching their systems like hawks, noticed the number of connections increasing again. Rapidly. With another system crash imminent, the experts decided it best to re-start the database and take a look in the morning.
In the end, the problem was tracked down to a single unchecked application, running on all the DCS computers. “It was not one ‘bad guy’, but a ‘bad guy’ on each system,” explains Stefan. In other words, the thousands of connections weren’t all emanating from one computer, but were spread across many.
The hero of the story is database administrator Luca Canali, who discovered that the process causing the multiple connections was using an admin account that had expired unnoticed when the original holder left CERN six months previously. The database refused to run any processes using the expired account, but the DCS process nevertheless continued to make requests, each time leaving an open session. Eventually, there were so many open sessions running, that the database simply said “no more” and shut down.
“In the end, if you find the right person, who knows the good piece of information, then you are done,” Stefan says, “but until you find that person, it takes a while.” In this case, the detective story of false leads and dead ends lasted almost 24 hours.
“No one person was at fault: it was just a communication flaw,” says Stefan in the aftermath of all the excitement. “ATLAS is huge; people are arriving, people are leaving. No-one has the full picture, so sometimes things like this happen … the expiration of this account slipped through the fingers of everybody.”
“The system is so complex,” adds Run Coordinator Christophe Clement, “that’s why we have these test periods.”
Of course, every good story has a moral. The incident highlighted just how much ATLAS’s running depends on the database, and there is now a rush to redirect the hefty chunk of other, benign, processes which were found to be accessing the database mid-run.
“We are even thinking for the next combined run, to unplug [the database] deliberately to see that now we are actually OK for this kind of thing,” says Stefan decisively. “You always learn something.”

Ceri PerkinsATLAS e-News
|