
ATLAS e-News
23 February 2011
PC farm for ATLAS Tier 3 analysis
4 May 2009
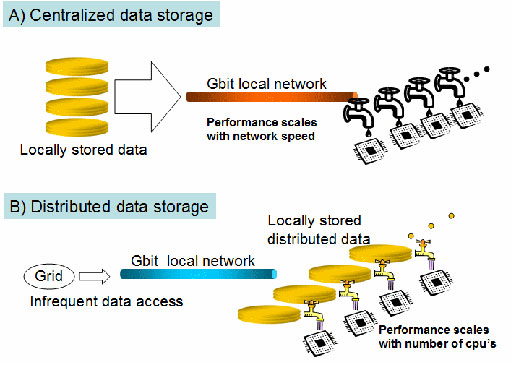
A) Parallel processing in a traditional cluster. For ATLAS analyses, the performance is limited by the network bandwidth. B) Parallel processing in a distributed data cluster. The performance scales as the number of PCs.
Arrival of ATLAS data is imminent. If experience from earlier experiments is any guide, it’s very likely that many of us will want to run analysis programs over a set of data many times. This is particularly true in the early period of data taking, where many things need to be understood. It’s also likely that many of us will want to look at rather detailed information in the first data – which means large data sizes. Couple this with the large number of events we would like to look at, and the data analysis challenge appears daunting.
Of course, Grid Tier 2 analysis queues are the primary resources to be used for user analyses. On the other hand, it’s the usual experience from previous experiments that analyses progress much more rapidly once the data can be accessed under local control without the overhead of a large infrastructure serving hundreds of people.
However, even as recently as five years ago, it was prohibitively expensive (both in terms of money and people), for most institutes not already associated with a large computing infrastructure, to set up a system to process a significant amount of ATLAS data locally. This has changed in recent years. It’s now possible to build a PC farm with significant ATLAS data processing capability for as little as $5-10k, and a minor commitment for set up and maintenance. This has to do with the recent availability of relatively cheap large disks and multi-core processors.
Let’s do some math. 10 TB of data corresponds roughly to 70 million Analysis Object Data (AOD) events or 15 million Event Summary Data (ESD) events. To set the scale, 70 million events correspond approximately to a 10 fb-1 sample of jets above 400-500 GeV in PT and a Monte Carlo sample which is 2.5 times as large as the data. Now a relatively inexpensive processor such as Xeon E5405 can run a typical analysis Athena job over AOD’s at about 10 Hz per core. Since the E5405 has 8 cores per processor, 10 processors will be able to handle 10 TB of AODs in a day. Ten PCs is affordable. The I/O rate, on the other hand, is a problem. We need to process something like 0.5 TB of data every hour. This means we need to ship ~1 Gbits of data per second. Most local networks have a theoretical upper limit of 1 Gbps, with actual performance being quite a bit below that. An adequate 10 Gbps network is prohibitively expensive for most institutes.
Enter distributed storage. Figure 1A shows the normal cluster configuration where the data is managed by a file server and distributed to the processors via a Gbit network. Its performance is limited by the network speed and falls short of our requirements. Today, however, we have another choice, due to the fact that we can now purchase multi-TB size disks routinely for our PCs. If we distribute the data among the local disks of the PCs, we reduce the bandwidth requirement by the number of PCs. If we have 10 PCs (10 processors with 8 cores each), the requirement becomes 0.1 Gbps. Since the typical access speed for a local disk is > 1 Gbps, our needs are safely under the limit. Such a setup is shown in Figure 1B.
At the Argonne ATLAS Analysis Center (ANL ASC), we’ve developed a PC farm, and the control software, based on the ideas discussed above. It is described in the ATLAS Communication note ATL-COM-GEN-2009-016. The design uses commodity hardware and well-established, and robust, software making it very stable and easy to set up as well as to use. The performance scales with the number of PCs making it easy (and inexpensive) to start with a small system and expand as needs arise. The control software is designed to handle general programs, not only Athena jobs. A 30% (24 core) prototype system has been operating at the ANL ASC since September 2008. The performance is as we expect for the system of this size; we find it very reliable and, for many tasks, faster than doing the equivalent processing on the Grid.
This PC farm design is one of the model Tier 3 described in the recent US ATLAS Tier-3 Task Force report. A web documentation with a step-by-step guide to building an ANL type PC farm is being developed. The first meeting to organize setting up a US ATLAS Tier 3 is to take place at Argonne on 18th and 19th May. Further information on this meeting can be found on the meeting site.

Sergei ChekanovArgonne National Laboratory |

Rik YoshidaArgonne National Laboratory
|