
ATLAS e-News
23 February 2011
A perspective on the successes of FDR-1
10 March 2008
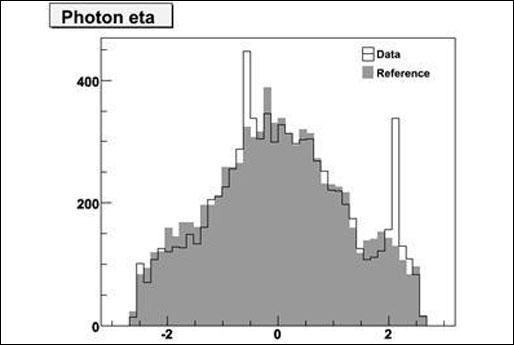
Problems were introduced for a short time to see if they could be detected. On the above plot, some hot channels were added artificially and were easily detected by the data quality monitoring system.
If the LHC turned on tomorrow, what would happen to the recorded data? There are models for data processing, quality evaluation, detector calibration, and data distribution, and there are software and hardware components to implement these models, but do they really work?
To answer these unsettling questions, we have undertaken a full dress rehearsal (FDR) of the ATLAS offline infrastructure, a realistic simulation of all computing components and data-preparation steps on the path from writing raw-data files from the data-acquisition system to analysing these data at remote computing centers. The ongoing first phase of this exercise, FDR-1, culminated during 5–8 February, when simulated collisions data in bytestream format were moved from Point-1 to Tier-0 at the anticipated LHC startup rate, and real-time processing and distribution were tested.
Was it a success? The question is a bit like asking whether it is successful when you bring your luxury automobile to the auto mechanic and are told that, although the engine basically works, it needs a large number of parts and adjustments before it will be road worthy. Our collaboration is both the mechanic and the driver; considered as a diagnostic exercise, the FDR-1 was felt to be successful by those of us working closely on it. The true success of the FDR-1 will be judged during the second phase (FDR-2) and at LHC startup, when we will see whether this exercise was realistic enough to find and fix a sufficient number of problems to allow reliable future running.
The simulated samples for FDR-1 ultimately include eight runs at a luminosity of 1031 cm-2s-1 with no samples to enhance the background trigger rate, two runs at 1031 cm-2s-1 with enhanced-background samples passing e/γ triggers, and one run at 1032 cm-2s-1 with no enhanced-background samples (although the 1032 cm-2s-1 run was not finished in time to be included in the Tier-0 exercises during the FDR-1 run). The production of these samples was difficult: many valuable lessons were learned about our software infrastructure, and a number of changes have already come about as a result. The data were written to bytestream-format files according to the streaming model, split across five sub-farm outputs (SFO) and at 2-minute luminosity-block boundaries. The final rates for the 1031 cm-2s-1 samples were lower than expected—the trigger menu at that luminosity selects background events predominantly, of which there were too few included in the simulated samples to achieve a realistic event mixture.
Although the simulated sample was smaller than hoped for, it was plenty to test the real-time performance of Tier-0 operations for four days, including fast turnaround of calibrations and data-quality checks by the detector and combined-performance groups. The express stream was processed promptly upon arrival from Point-1, and within hours after the last parts of the run were reconstructed, people were able to spot problems in the data, both planned and unplanned, using the data-quality histograms. An inner-detector alignment stream was produced for the first time, and the alignment group was able to use it to provide initial alignment constants. This was done starting from a completely unaligned detector within two days, although much of the computing was done outside CERN during those days. Daily decisions of whether to reconstruct and export the physics streams were made based on available data-quality information and calibration constants. After some initial hiccups, the reconstructed data (AODs, ESDs, and TAGs) were completely and quickly exported to Tier-1 and Tier-2 sites according to the distribution model.
The FDR-1 continues at the Tier-1 and Tier-2 sites even now, while preparations for a May FDR-2 are underway. At the Tier-1 sites, the data will be reprocessed, and first attempts at centralized DPD ("derived physics data") production will be made. Around the world, interested analysts are now looking at the data, with an eye toward the coming excitement of analyzing the first LHC data. For FDR-2 we will produce simulated samples corresponding to a higher luminosity and including pile-up and cavern background. More calibration procedures will be tested, including the muon-calibration procedure involving processing at Tier-2 sites. We will attempt prompt luminosity and beam-spot determinations, trigger-menu prescale variations, trigger- and time-dependent monitoring with automatic checks, and integration of data-quality checks at Tier-1 sites for reprocessing. As with FDR-1, we expect FDR-2 to be difficult and eye opening, but with the prospect of LHC data within the year, we must make maximal use of these exercises to diagnose and fix the lurking errant components in our computing models.

Michael G. Wilson
CERN